CUEJ master 2 2019/20 - Elections européennes 2019
Organisation
On va avoir plein de fichiers. Il faut s'organiser, faire des sauvegardes fréquentes, des sous-dossiers, découper ses programmes en fonction des tâches, etc. C'est VRAIMENT important, sous peine de perdre un temps fou.
R
Lancer R
En principe, R est installé sur les Macs.

C'est rustique :
Premiers pas
Tapez les commandes suivantes, les unes après les autres, suivie de "Entrée" :
3 + 6 8^2 a <- 4 b <- 5 a * b a == b a < b a b a * b c <- 'c' d <- 'd' c + d paste(c, d, sep = '')
A retenir :
- Pas besoin de typer explicitement les variables
- L'opérateur d'affection est <- (= fonctionne aussi)
- Les opérateurs arithmétiques et les opérateurs de comparaison
- Lire les messages d'erreur... LIRE LES MESSAGES D'ERREUR :-)
- Différence entre valeurs numériques et chaînes de caractère
- La syntaxe des fonctions : motClé(arguments séparés par des virgules)
Référence : les opérateurs R
Deux interfaces pour R :
- RStudio (IDE)
- RCommander("vraie" interface graphique, mais on ne va pas s'en servir, on est des codeurs !)
Rstudio

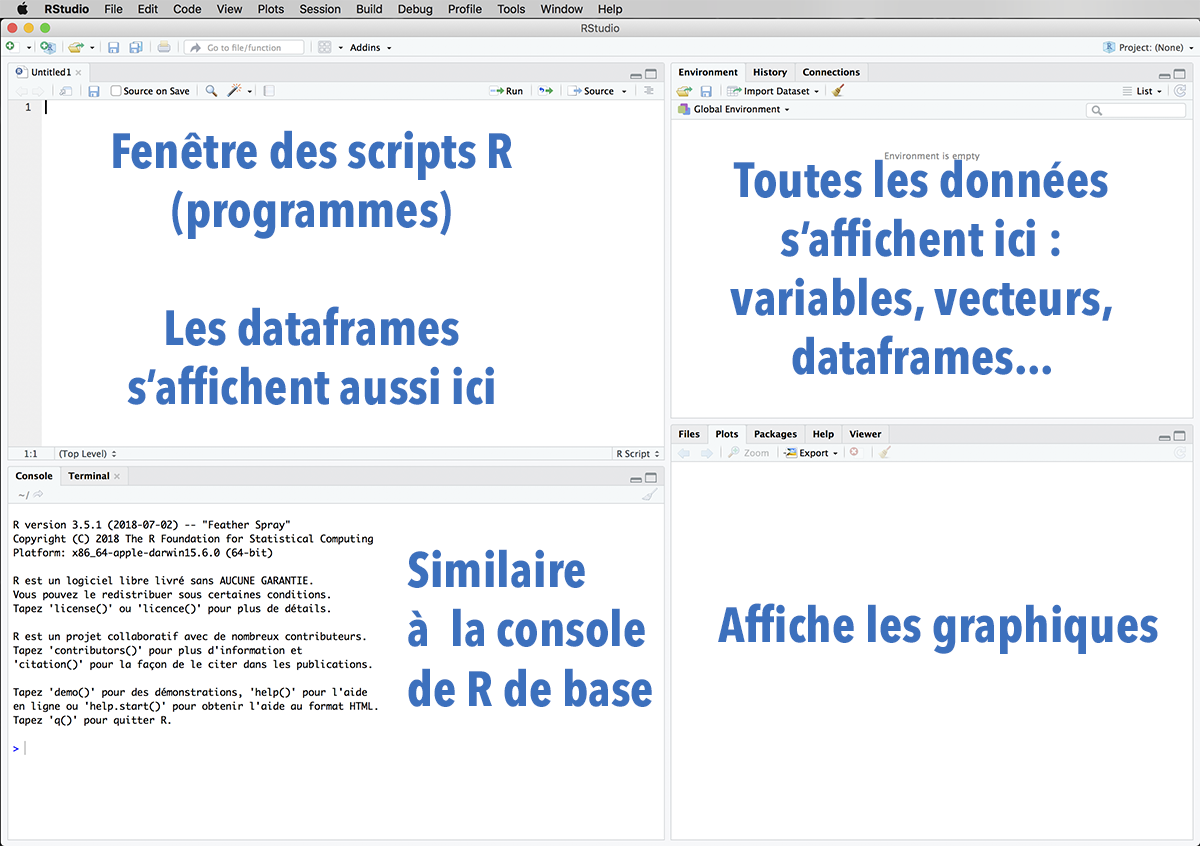
Définir le répertoire de travail
- Définir un répertoire de travail permet de ne pas avoir à taper de long chemins de fichiers.
- R cherchera les fichiers dans ce répertoire.
- Si on change les fichiers de place, on aura juste une ligne à modifier.
Exemple :
setwd("/Users/eguidat/Documents/Cours/cuej2-18/files")
ou bien
setwd("~/Desktop/Seafile/CUEJM2/CUEJ18-19")
setwd = Set Working Directory
Les vecteurs
Dans la fenêtre de scripts, tapez :
vec1 <- c(1, 2, 3) vec2 <- c(2,3,4)
Puis :
- Sélectionnez les deux lignes
- Appuez sur Commande + Entrée
Notez que les vecteurs sont visibles dans la fenêtre Environment
Essayez :
vec1 + vec2 vec1 * vec2 sum(vec1) mean(vec2)
On peut aussi stocker des chaines (mais pas mélanger numérique et chaînes) :
vec3 <- c('Rouge', 'Vert', 'Bleu')
vec4 <- c('carmin', "d'eau", 'azur')
vec5 <- paste(vec3, vec4, sep = " ")
vec5
A retenir :
- Sélection puis Cmd + Entrée pour exécuter une partie d'un programme
- 'c' est la fonction qui crée un vecteur
- ATTENTION : les noms des variables sont sensibles à la casse !! Vec3 et vec3 sont deux vecteurs différents
- Deux nouvelles fonctions : sum et mean
- Les apostrophes c'est pénible
- La fenêtre de script colorie automatiquement la syntaxe
- Elle tente aussi de prédire ce que vous voulez taper
- Les variables créées le sont pour la durée de la session. Quand on quitte R, elles sont effacées
- Mais on peut sauver le script, qui n'est que du texte
- On peut aussi sauver des données, on le verra plus tard
Essayez :
villeA <- c(1503, 1458, 125, 128)
villeB <- c(3851, 3275, 410, 415)
villeA[2]
villeA[c(1, 4)]
villeA[1:3]
noms <- c("femmes", "hommes", "naisF", "naisG")
names(villeA) <- noms
names(villeB) <- noms
villeB['femmes']
Exercice : déterminer si le taux de natalité de la ville B est supérieur à celui de la ville A. Le taux de natalité est le rapport de l'ensemble des naissances à l'ensemble de la population
naisA = sum(villeA[c('naisF', 'naisG')])
popA = sum(villeA[c('femmes', 'hommes')])
txNatA = naisA / popA
naisB = sum(villeB[c('naisF', 'naisG')])
popB = sum(villeB[c('femmes', 'hommes')])
txNatB = naisB / popB
txNatB > txNatA
Les matrices
Essayez :
villesAB <- matrix(c(1503, 1458, 12, 13, 3851, 3275, 41, 45), byrow = TRUE, nrow = 2)
Cliquez (une fois) sur villeAB dans l'onglet Environment.
Exercice : intuitivement, essayez de trouver une syntaxe plus simple.
villesAB <- matrix(c(villeA, villeB), byrow = TRUE, nrow = 2)
Exercice : comme nous l'avons fait pour les vecteurs, esayez de donner des noms aux colonne et aux lignes de cette matrice. Indice : rawnames() et colnames()
nomsCol <- c("femmes", "hommes", "naisF", "naisG")
nomsLig <- c("villeA", "villeB")
colnames(villesAB) <- nomsCol
rownames(villesAB) <- nomsLig
villesAB
# Autre solution, plus compacte
villesAB <- matrix(
c(villeA, villeB),
byrow = TRUE,
nrow = 2,
dimnames = list(
nomsLig, nomsCol
)
)
A retenir :
- Dans la deuxième solution, notez comment on peut indenter son code pour le rendre plus lisible
- Notez aussi le caractère # qui permet de commenter son code. C'est très important pour s'y retrouver dans des programmes longs, ou lorsqu'on revient sur un programme après quelque temps.
Essayez :
villeC <- c(3002, 2896, 59, 60) villesABC <- rbind(villesAB, villeC) sommesCol <- colSums(villesABC) sommesLig <- rowSums(villesABC) villesABC <- rbind(villesABC, sommesCol) villesABC <- cbind(villesABC, sommesLig)
Notez le warning. C'est différent d'une erreur. L'instruction s'est exécutée mais il y a eu un truc bizarre.
Exercice : corrigez le programme pour éviter le warning
villesAB <- matrix(c(1503, 1458, 12, 13, 3851, 3275, 41, 45), byrow = TRUE, nrow = 2)
villesAB <- matrix(c(villeA, villeB), byrow = TRUE, nrow = 2)
nomsCol <- c("femmes", "hommes", "naisF", "naisG")
nomsLig <- c("villeA", "VilleB")
colnames(villesAB) <- nomsCol
rownames(villesAB) <- nomsLig
villesAB
# Le tout en une seule commande
villesAB <- matrix(
c(villeA, villeB),
byrow = TRUE,
nrow = 2,
dimnames = list(
nomsLig, nomsCol
)
)
villeC <- c(3002, 2896, 59, 60)
villesABC <- rbind(villesAB, villeC)
sommesCol <- colSums(villesABC)
villesABC <- rbind(villesABC, sommesCol)
sommesLig <- rowSums(villesABC)
villesABC <- cbind(villesABC, sommesLig)
Essayez :
villesABC[,2] villesABC[,'hommes'] villesABC[3,] villesABC['villeC',] villesABC[2,3] villesABC['villeA', 'naisF'] villesABC[1:3, 2:3]
Les facteurs
Essayez :
tailles <- c("g", "g", "m", "p", "g", "p", "m", "g", "p")
summary(tailles)
fTailles <- factor(tailles)
levels(fTailles)
summary(fTailles)
fTailles <- factor(tailles, order = TRUE, levels = c("p", "m", "g"))
levels(fTailles)
summary(fTailles)
levels(fTailles) <- c("petit", "moyen", "grand")
levels(fTailles)
summary(fTailles)
A retenir :
- Les facteurs stockent des variables nominales au sens statistique
- Ces varibales nominales peuvent être ordonnées, elles deviennent alors ordinales
- La fonction summary
Les tableaux de données
Les tableaux de données, ou date frames, combinent tout ce que nous avons vu jusqu'à présent.
Essayez :
#1.
femmes <- c(1503, 3851, 3002, 6120, 150, 305)
hommes <- c(1458, 3275, 2896, 5996, 146, 298)
naisF <- c(41, 59, 131, 2, 3, 5)
naisG <- c(13, 45, 60, 142, 2, 4)
type <- factor(c("rural", "urbain", "peri", "urbain", "rural", "rural"))
richesse <- factor(c("riche", "moyen", "pauvre", "moyen","riche", "pauvre"),
order = TRUE,
levels = c("pauvre", "moyen", "riche"))
politique <- factor(c("gauche", "droite", "gauche", "gauche", "droite", "centre"))
villes <- c("villeA", "villeB", "villeC", "villeD", "villeE", "villeF")
df <- data.frame(
femmes, hommes, naisF, naisG, type, richesse, politique,
row.names = villes
)
#2.
str(df)
df[,3]
df[4,]
df[2,4]
df["villeC",]
df["villeD","femmes"]
# 3. Une manière aisée de sélectionner une colonne dans un data frame
df$naisF
#4. pour sélectionner des lignes selon une condition ou des conditions
subset(df, politique == "gauche")
subset(df, politique == "gauche" & naisG > 40) # le signe pour 'ou' est |, alt+maj+L sur un Mac
#5. les trucs vus avant marchent toujours
sum(df$hommes)
L'aide
Pour obtenir de l'aide sur une fonction, il faut taper ? suivi du nom de la fonction, sans espace
?c ?str
Sauvegarde
Pensez à sauver souvent votre programme. R est très stable mais on ne sait jamais.
Le programme n'est qu'un simple ficher texte. Il ne comporte pas les données.